RAG against the infinite context machine: unit economics is all you need

In their seminal paper titled “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks” Facebook’s AI Research team put forth several motivations for Retrieval Augmented Generation (RAG) but the bottom line was this: language models were not good enough for knowledge-based tasks. RAG was mooted primarily as a technique to make them better, not cheaper.
By the launch of GPT4 our collective experience is that best-of-class LLMs are indeed capable of knowledge-based tasks, for knowledge captured in data that they were trained on. But what about data that was not available to training, either because the data is non-public or is new, postdating the training of the LLM?
In that scenario we have no choice but to include the missing data within the query. But what if the data in question is a 300 page PDF dissertation?
Why is/was Retrieval Augmented Generation necessary?
All through 2023, there was only one way to practically use a LLM with a 300 page document:
- Chunk up the 300 page dissertation into smaller pieces.
- Load the chunks into a vector database.
- When handling a query, retrieve N most relevant chunks from the vector database.
- Include those chunks as context within a prompt, and present the prompt to the LLM.
- Return the completion to the user.
Why are steps 1-3 necessary? Why can’t we simply include the full 300 page document as context with the prompt? Without the vector database and retrieval step we could still direct a generic large language model to interrogate our proprietary documents, simply by including the entire document contents as context within the prompt in step 4. Indeed there are generative AI practitioners who advocate such an approach. But there have been several downsides and limitations with this approach:
- Context window limitations. Current generally available large language models are based on an architecture which has a finite context window size. This means that very large documents, or collections of large documents, will be too large to fit into query size limits.
- Cost. The computational expense of large language model lookups increases with the size of the query context window, which reflects in the pricing model of most commercial API-based implementations.
- Quality. In “Lost in the Middle: How Language Models Use Long Contexts”, researchers showed data indicating that very large queries suffer performance issues due to inconsistent weighting of query contents.
Those are the reasons why, up to early 2024, Retrieval Augmented Generation remains a common practice.
Here we present our findings from an experiment looking into the cost factors of RAG. We count embedding tokens as a proxy for cost, making no attempt to distinguish between types of tokens, though mainstream platforms do price input and output tokens differently; for the purpose of our evaluation, we feel we can gloss over this distinction for now.
Our use case involves a 12 page service agreement from a healthcare service provider, and the task is to determine what specific services are being included in the agreement and to format the result in a specific human-readable format. In a Full Context implementation, the full 12 page service agreement contents were attached to the user query to form the final LLM prompt. In a RAG implementation, the service agreement was loaded into a vector database and the query was used to retrieve the top-3 matching chunks which were attached to the user query to form the final LLM prompt. Both implementations used gpt-3.5-turbo as the LLM, and the RAG implementation used the text-embedding-3-small embedding model.
Naturally the LLM prompt size for RAG would be significantly lower than the prompt size for Full Context, but we have to pay attention to some “hidden costs” of RAG:
- The cost of embedding the full document prior to loading into the vector database.
- The cost of embedding the query to perform vector database matching to retrieve relevant chunks.
- The operational cost of the vector database.
Let’s ignore 3 for now. The result of the test query was very similar for both the Full Context implementation and the RAG implementation. Taking one sample completion, the RAG implementation output was slightly longer. We tallied up the token consumption for both implementations.
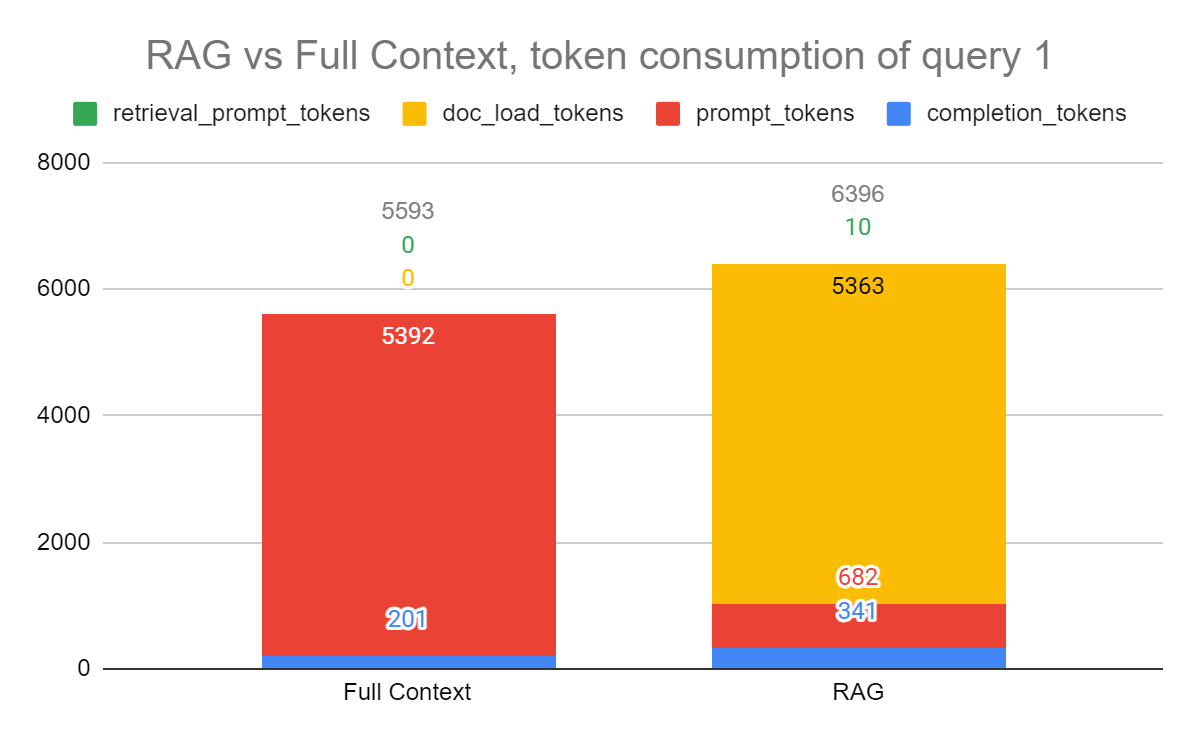
The results clearly illustrate the one-time cost of embedding a document is substantial, which makes intuitive sense. But this is for ‘query 1’; in subsequent queries that leverage the same document, doc_load_tokens reduces to zero, and consequently we may expect RAG to ‘break even’ by query N by amortizing the one-time doc_load_tokens cost. It turns out, for this experiment, RAG pays for itself by query 2.
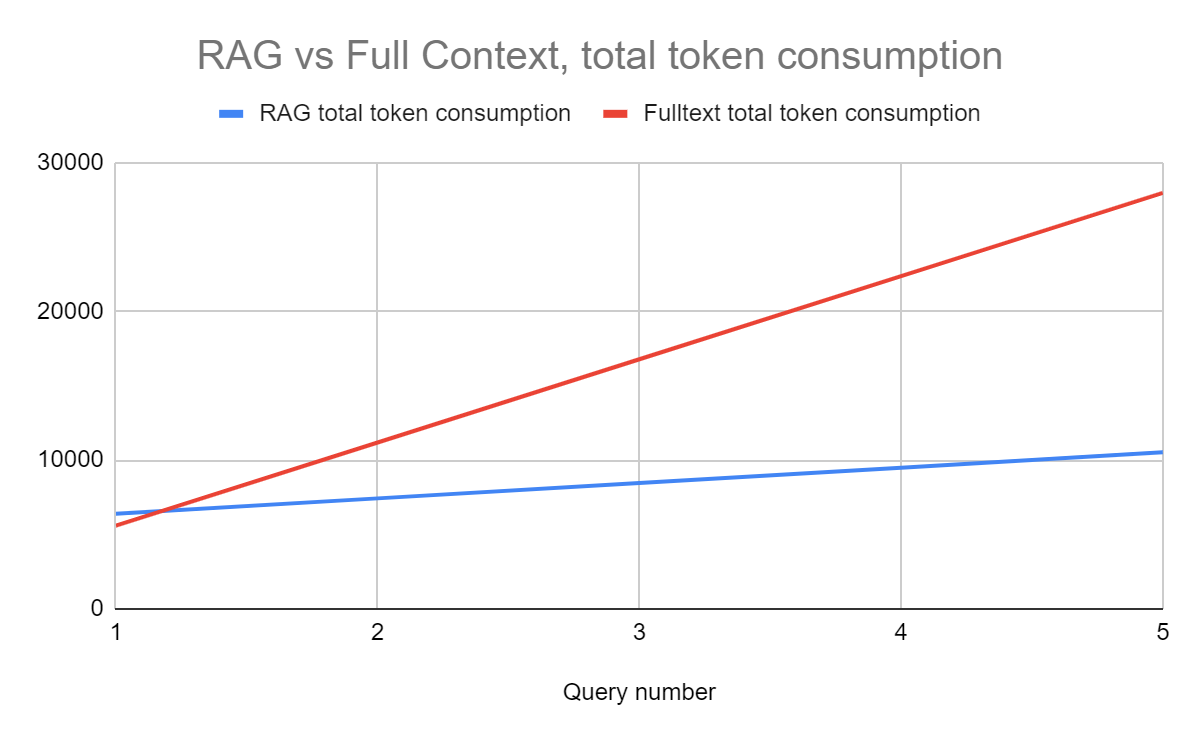
Revisiting point 3, we haven’t accounted for the cost of operating the vector database. Although this is an omission, we believe it is not a consequential omission because under the hood a vector database is a lot less magical than an LLM (in fact one suspects close examination may reveal that the market leading vector database could be sqlite), and with the unit economic advantages of RAG being so significant, there is more than adequate margin for vector database operational cost.
Will Retrieval Augmented Generation become obsolete by the end of 2024?
Let’s /imagine all the above issues can be addressed through foundation model design innovation, with promising methods like ring attention design.
A breakthrough in context length will be a game changer for many applications, including multimodal and especially video models. But would it deprecate the need for RAG pipelines?
AI applications can be quick and cheap to prototype and demo, but expensive to scale, optimize, and maintain.
When it comes to LLM applications, the topic of unit economics gets insufficient attention, so we’re going to post more on this topic, particularly from our experience developing applications. Please subscribe so you won’t miss future posts on this topic.
From an engineering perspective, RAG pipelines offer something that is very valuable compared to querying an LLM directly: probe/injection points. Because a RAG pipeline has a discrete information retrieval step, there is the opportunity to probe retrieval output or inject retrieval modification before it progresses to the LLM. This creates several opportunities:
- White-box testing and optimization. Because it’s possible to evaluate retrieval performance without any side effects from the LLM, it becomes easier to root cause and address performance issues. Trulens has popularized this approach as the so-called RAG triad.
- Granular data masking and routing. With a RAG pipeline it is possible to observe the results of a retrieval and make a policy determination about what to do with it. Does the retrieval result contain PII? Then mask it, or route the query to a locally hosted LLM instead. Does the retrieval result fail any safeguard checks that may be related to a data poisoning prompt injection attempt? Once again we have a probe point where this can be addressed at query time, reducing the risk of harm and increasing assurance.
- Serialization of complex data structures. How would you RAG on a major git repository where commit messages are tied to Jira tickets? This is starting to segue into a vision of agentic RAG, particularly when contemplating data domains with multihop properties, but in situations where data entities have internal or external relationships, serialization becomes non-trivial and depends on the nature of the underlying data assets, which lends itself naturally to a retrieval step. RAG looks like an ugly hack only through the lens of someone who sees the world as a folder full of PDFs.
These operational benefits will be hard or uneconomical to replicate in systems which do not leverage a discrete adaptive retrieval step. That’s why in our view, Retrieval Augmented Generation is not going to disappear so soon.