Reliable RAG: preprocessing is all you need
Give your RAG pipeline an edge in reliability and efficiency, with propositional chunking
Under the hood of every “chat with your PDF” generative AI application, there is a keystone piece of infrastructure: a RAG pipeline. Retrieval-Augmented Generation (RAG) is the practice of incorporating custom data sets in generative AI workflows, and the results can be magical, at least in the beginning. RAG-powered chatbots tend to present extremely well in demos, but production-grade reliability, accuracy, and precision often proves to be elusive. That’s because the RAG practices of 2023/2024 have overlooked a simple long-standing tenet of information technology: garbage-in, garbage-out.
The view that Artificial Intelligence is somehow magical can be deeply counter-productive because it can lead us to miss low-hanging fruit for systemic improvement. Let’s think step-by-step about how large language models really work in the context of RAG pipelines. When viewed as an end-to-end system, it becomes clear that throwing unprocessed human-optimized artifacts at a RAG pipeline cannot always be optimal. In this article we’ll show that, when it comes to RAG performance, data preprocessing is all you need.

Proposition-based retrieval outperforms traditional methods for both retrieving passages and question-answering tasks. Two approaches are used for retrieval; Izacard et al. or Ni et al. Recall@k is the percentage of questions for which the correct answer is found within the top-k retrieved passages, while EM@100 (Exact Match at rank 100) is the percentage of responses matching ground truth when evaluating only the top 100 retrievals. Figure source: Chen et al.
This post is written for anyone who will lead a project to leverage proprietary data in LLM applications. There are two tracks:
- First time building a RAG pipeline? Continue to the section reviewing the concepts and mechanics of Retrieval Augmented Generation.
- Already familiar with RAG? You may wish to skip ahead to our recommendations on data preprocessing.
The case for preprocessing
Why can’t large language models pre-process RAG documents on their own? The answer is intrinsically tied to the very motivation to use RAG in the first place, and it relates to the architecture of RAG pipelines and the concept of context windows.
If you are already familiar with Retrieval Augmented Generation and the architecture of RAG pipelines, you may skip ahead to the section on propositional chunking, a simple data preprocessing technique that yields significant performance gains for RAG pipelines. But a refresher never hurts, so here is what you need to know about RAG and RAG pipelines.
1 What is Retrieval Augmented Generation?
Retrieval-Augmented Generation (RAG) is the practice of incorporating custom user-provided data sets in generative AI workflows. This is done to augment the capabilities of Large Language Models (LLMs) with data that was not included in its original training dataset.
LLMs are the result of training on large, but finite, amounts of data. Once trained, LLMs may be fine-tuned with additional data. However, fine-tuning processes are costly and time-consuming, and ultimately, are still constrained in the amount of data that can be included.
RAG is a flexible paradigm whereby LLMs can leverage data that may be proprietary and non-public, or data that was simply not available at the time that the LLM was trained.
%%{init: {'theme': 'base', 'themeVariables': { 'fontSize': '42px'}}}%%
flowchart LR
classDef bigfont font-size:20px;
newLines["Custom Data + LLM + x = Profit\n\nSolve for x"]
class newLines bigfont
Solving for x is the “now draw the rest of the owl” of business and AI. Hint: the answer is not x = Profit - LLM - Custom Data.
RAG has several properties that are very attractive to business initiatives:
-
Data-as-a-moat. The business thesis driving interest in RAG is the idea that data within a business has high potential as a source of competitive advantage. RAG is one technique to allow businesses to leverage that data.
-
Capital-light. RAG does not require any investment in training or hosting a proprietary LLM. Additional investment in vector databases may be required, particularly if there is a requirement for data to remain on-premise. But, this is significantly lower than the cost of hosting and operating a fully custom LLM. Even fine-tuning a generic LLM requires up-front cost that needs to be amortized through unpredictable value from queries. Capable open source models have been shown to be practical to train and operate on commodity hardware, but these usually lag the state-of-the-art models. Nevertheless, well-tuned open source models may suffice for some use-cases, but they won’t hold up against scope creep.
-
Rapid time-to-value. Training a custom LLM, or even fine-tuning a generic LLM, requires investment in time before value can be extracted from the first query. Setting up a RAG pipeline is considerably faster, and lends itself well to experimentation and exploration, where use cases are not completely defined ahead of time.
-
Operational adaptability. Training or fine-tuning a LLM, generally speaking, results in an immutable high-cost asset. Once trained, it can be tricky if not impossible to adequately address constraints due to compliance or other factors, such as responding to ‘right-to-be-forgotten’ requests, emerging data sovereign requirements that were not in place at time of training, data quality issues (including data poisoning) discovered post-training, etc. With RAG, proprietary data is not incorporated into the LLM, so responding to compliance changes is feasible through familiar approaches such as data leakage prevention and masking. Even if re-indexing data is required, this is still relatively feasible as it may be thought of as a database migration operation at worst.
In short, RAG combines the power of LLMs with the operational paradigms of databases, resulting in the best of both worlds. There are use cases where approaches like fine-tuning could yield better outcomes than RAG, such as alignment with output ‘style’ requirements (e.g. brand guideline conformity), but in a general sense, for any data-as-a-moat use case, in our view RAG should be plan A.
Retrieval Augmented Generation does not, by definition, require a vector database. For use cases involving queries on small documents, it may suffice to simply attach the entire contents of the document with the query, resulting in a bare-bones prompt that may look like this:
Respond to the query (delimited by triple backticks)
based on the contents of the context (delimited by
triple backticks).
QUERY: ```{query}```
CONTEXT: ```{full_doc_text}```This simple approach may be appropriate for small documents that contain only a small amount of information, but this approach will not scale for large documents or collections of documents, for the following reasons:
- Context window limitations. The prompt must be below a certain size, as limited by the target LLM.
- Token costs. Even if your prompt size fits within the token limit of a given LLM, usually you pay more for larger prompts.
- Response quality issues. Giving the LLM irrelevant context can yield poorer, e.g. less “grounded”, responses.
For these reasons, it is often advisable to introduce a discrete information retrieval step to generate context for a prompt (replacing full_doc_text with a subset, or chunks, of source documents), and that typically involves a vector database.
2 What is a RAG pipeline?
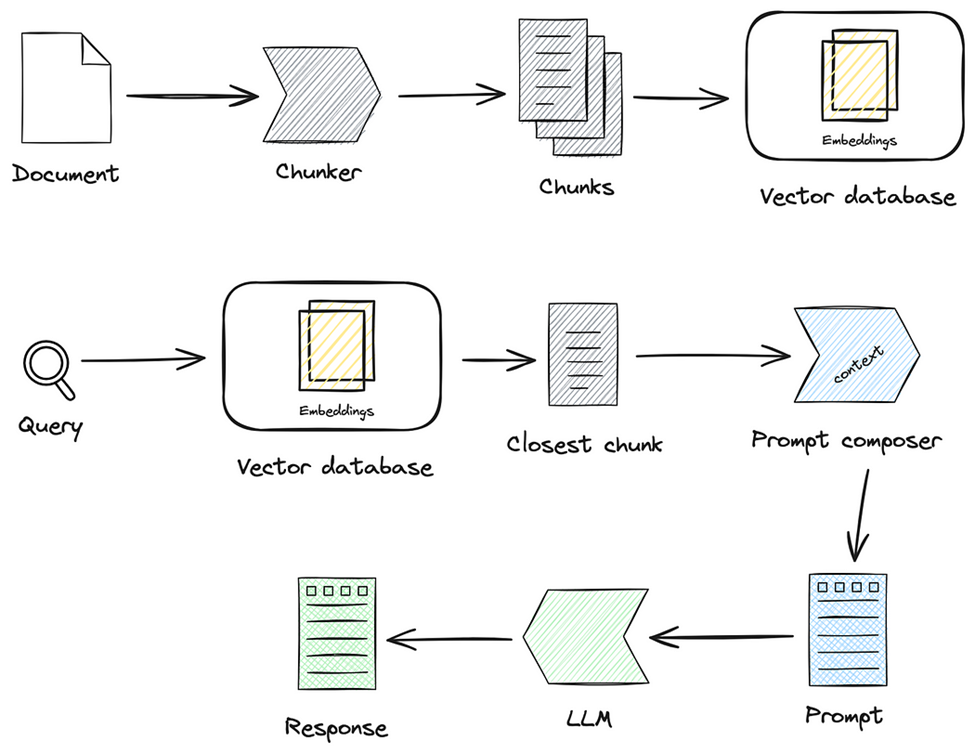
There are two sides to a RAG pipeline: document load and query response. Both sides are connected via a vector database. In real-world deployments, multiple documents may be loaded continuously, concurrently to query response, but architecturally they are independent processes.
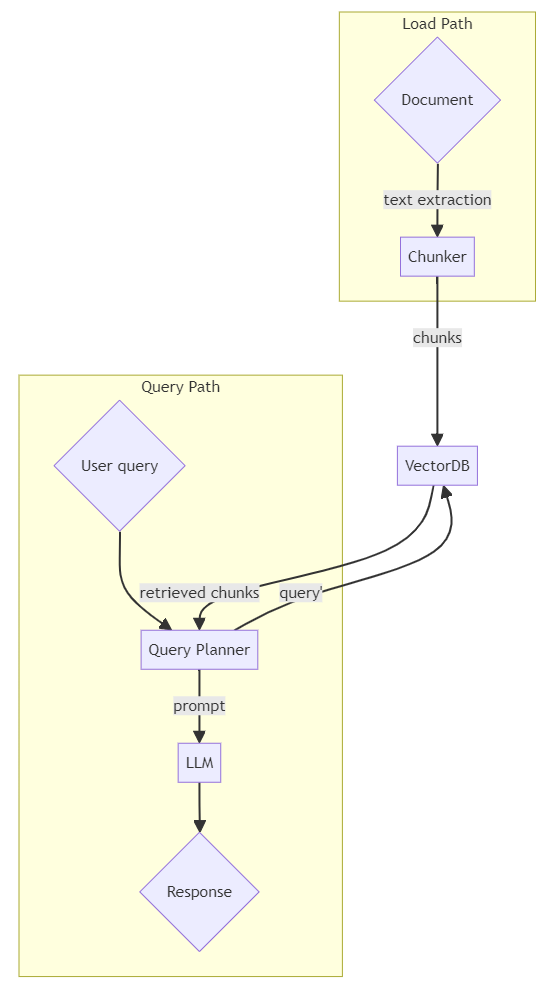
Conventional RAG architecture.
For simplicity’s sake, let’s assume the case of a single document that is loaded before queries begin.
On the document load side, in preparation for this step in the RAG pipeline, the source document is subject to chunking and embedding to convert its content into a mathematical form. This form is stored in a specialized vector database and indexed to expedite the retrieval process.
A vector database (vector DB) is specializes in storing and searching high-dimensional vectors representing complex data like text and images, ideal for similarity searches in unstructured datasets. In contrast, SQL databases organize data into structured tables and rows, which are well-suited to transaction processing and complex queries over structured data.
NoSQL systems like MongoDB and Cassandra are also optimized for unstructured and semi-structured use cases, but vector DBs are specialized for similarity searching, which is required for use cases such as recommendation systems and information retrieval. The ability to flexibly and efficiently deliver similarity searching over unstructured data is why vector DBs are commonly used as part of RAG pipelines.
Examples of widely used vector DBs include Chroma DB, Qdrant, Pinecone, and Weaviate. To complain that we forgot to mention your favorite vector DB, please email [email protected].
On the query side, a RAG pipeline starts when a user inputs a query, accompanied by a prompt, into the RAG interface. The query will typically pertain to tasks such as answering questions from a specific source or aggregate scope-specific summarisation over multiple sources. Once inputted, the query undergoes processing, which involves chunking and embedding, effectively transforming the text into a mathematical representation. This processed query is then forwarded to a Retrieval Engine, which extracts chunks or excerpts of the source document from the vector database.
At this stage, the RAG interface combines the initial query with the contextually relevant information retrieved from the vector database. This composite of application-layer prompt, user query, and information retrieved from the vector database forms the final query which is subsequently sent to a Large Language Model (LLM) to generate a response. The LLM, with the aid of both the query and the supplementary information provided by the RAG pipeline, formulates a coherent and relevant response. This response is finally delivered to the user via the RAG interface.
The compiled prompt that the LLM receives will be structured in some way to include: 1. Instructions 2. The retrieved context and 3. The user’s query:

Inserting full documents into LLM queries may not always be possible due to context window limitations; put simply, LLM query sizes are limited. But even when a document or set of documents is technically small enough to fit in the context window of some LLMs, such efforts face challenges like limited processing capacity, higher costs, and reduced performance. Despite potential future enhancements in LLM architecture such as ring attention design, RAG pipelines still enjoy performance, cost, and operational benefits. These advantages ensure RAG pipelines retain their value even as foundation model science and engineering continues to evolve.
As of Q1 2024, debate is raging on whether or not RAG will continue to be relevant if LLMs achieve practically unlimited context window size.
Our view is that RAG will continue to be relevant. Check out our post on the unit economics and practicalities of LLM applications to find out why.
3 A primer on chunking
In order to bring a document into a RAG pipeline, it is necessary to break it down, with a process called chunking. In a general sense, chunking involves dissecting and reorganizing unstructured data into a structured, composable format. This is necessary to ensure a systematic organization of data, and ideally to align with the intrinsic processing characteristics of LLMs. The process of chunking directly influences the quality of information fed into LLMs, specifically the precision and relevance of the retrieved content to the original query.
In short, chunking impacts the efficiency and accuracy of the retrieval process, which in turn, influences the quality of the result generated by the LLM.
There’s a common misunderstanding that a language model like GPT-4 actively ‘searches’ through entire documents to find answers to queries. In reality, the model does not comb through documents in their entirety. Rather, it processes pre-extracted sections of text – known as ‘chunks’ – to generate responses.
For example, from the well known State of the Union dataset, the query may be:
“What did the president say about Justice Breyer?”
Prior to the language model coming into play, the document is segmented into these manageable chunks. From the complete text:
Chunk 1: “Madam Speaker, Madam Vice President, our First Lady and Second Gentleman. Members of Congress and the Cabinet. Justices of the Supreme Court. My fellow Americans. Last year COVID-19 kept us apart. This year we are finally together again. Tonight, we meet as Democrats Republicans and Independents. But most importantly as Americans.”
…
Chunk N: “Justice Breyer, thank you for your service. One of the most serious constitutional responsibilities a President has is nominating someone to serve on the United States Supreme Court. And I did that 4 days ago, when I nominated Circuit Court of Appeals Judge Ketanji Brown Jackson. One of our nation’s top legal minds, who will continue Justice Breyer’s legacy of excellence. A former top litigator in private practice.”
Chunk N+1: “A former federal public defender. And from a family of public school educators and police officers. A consensus builder. Since she’s been nominated, she’s received a broad range of support from the Fraternal Order of Police to former judges appointed by Democrats and Republicans.”
When a query is made, the model doesn’t scan the original document; the RAG retriever evaluates these prepared chunks to identify which ones are most relevant to the query. It is these selected chunks, not the whole document, that the language model uses to construct a response. The retrieved context for this example is:
Chunk N: “Justice Breyer, thank you for your service. One of the most serious constitutional responsibilities a President has is nominating someone to serve on the United States Supreme Court. And I did that 4 days ago, when I nominated Circuit Court of Appeals Judge Ketanji Brown Jackson. One of our nation’s top legal minds, who will continue Justice Breyer’s legacy of excellence. A former top litigator in private practice.”
The retrieved chunk is inserted into the prompt and passed to the LLM to generate the final synthesised response:
“The president thanked Justice Breyer for his service and mentioned that he is retiring from the Supreme Court. The president also nominated Judge Ketanji Brown Jackson as a replacement for Justice Breyer.” The yellow highlight is the retrieved context.
4 Simplistic - but still mainstream in 2024 - approaches to chunking
Some naive chunking strategies are still commonly used in 2024. These methods are not yet obsolete, and are still useful due to their simplicity to implement and the affordance that retrievers make for returning the top-k chunks that may contain relevant information.
4.1 Fixed size-based chunking (character based text splitter)
Split the document into chunks of a specific size, regardless of semantics.

Image produced with ChunkViz by Greg Kamrandt.
A paragraph can be divided into chunks of equal character lengths. In the above example, the paragraph is split irrespective of whether sentences are cut mid-way.
4.2 Paragraph-based and sentence based (recursive character based splitter)

Image produced with ChunkViz by Greg Kamrandt.
Split the document based on “end of paragraph” characters, like “\n\n”, “\n”, “;” etc., or based on the end of sentences “.”.
5 Introducing semantic approaches to chunking
The chunking approaches mentioned above are purely syntactic. However, one would prefer to split the document into semantically distinct chunks.
Why?
The answer is precision in retrieval. During query time, the goal is to fetch text segments that align most closely with the semantic intent of the query. When chunks are semantically vague, they can yield irrelevant data, resulting in a dip in response quality and an uptick in language model errors. Furthermore, the likelihood of overlooking nuanced entities within the text increases, as does the chance of truncating additional context due to the constraints of the processing window.
This ‘meaning-conscious’ approach to chunking takes advantage of the theory behind semantic-based search methods inherent to the types of retrievers that are commonly used in RAG pipelines. In other words, we’re optimizing the data for the characteristics of the machine.
The idea is to build semantic chunks from the ground up.
- Start with splitting the document into sentences. A sentence is usually a semantic unit as it contains a single idea about a single topic.
- Embed the sentences.
- Cluster close sentences together forming chunks, while respecting sentence order.
- Create chunks from these clusters

Semantic chunking — semantic sentence clustering
How do we progress from syntactic and structure-based text splitting methods towards an effective semantic based approach? The intrinsic aspect of sentence based semantic clusters – “sentence clustering-based chunking”, is that the semantic similarity between sentences can be easily compared. To do this, the text must be modified/transformed/processed in a way that semantic relevance can be accurately attributed to the embedded sentences. Cue the hero of this blog post, propositional chunking.
What is propositional chunking
Propositional chunking is defined as the process of breaking down text into propositions. Propositions are atomic expressions within the text, each encapsulating a distinct fact, presented in a concise, clear, and self-contained natural language format. This method stands out for its focus on propositions as inherently self-contained units, ensuring that each chunked segment is minimal, indivisible, and conveys complete information independently.
The proposition, “The Leaning Tower of Pisa now leans at approximately 3.99 degrees,” exemplifies propositional chunking. It encapsulates a complete, standalone fact, with context relevant precision and independence. To further illustrate, consider the following example about the Leaning Tower of Pisa’s tilt degrees and displacement.

An example of three granularities of retrieval units of Wikipedia text when using dense retrieval.
From this passage we may derive the following propositions:
- The Leaning Tower of Pisa tilted 5.5 degrees before the 1990–2001 restoration.
- The Leaning Tower of Pisa now tilts 3.99 degrees.
- The top of the Leaning Tower of Pisa is 3.9 meters horizontally displaced from the center.
These propositions, each conveying precise facts, maintain narrow context for standalone interpretability without losing the passage’s complete meaning, demonstrating the strategic reimagining of text processing through propositional chunking. Content presented this way is arguably less enjoyable to read, but RAG pipelines are not built for the amusement and gratification of the AI.
How to incorporate propositional chunking into a RAG pipeline
To incorporate propositional chunking in your RAG pipeline, you need an additional load-side component: the propositionizer. And core to the functioning of a propositionizer is itself an AI model, which may be a LLM.
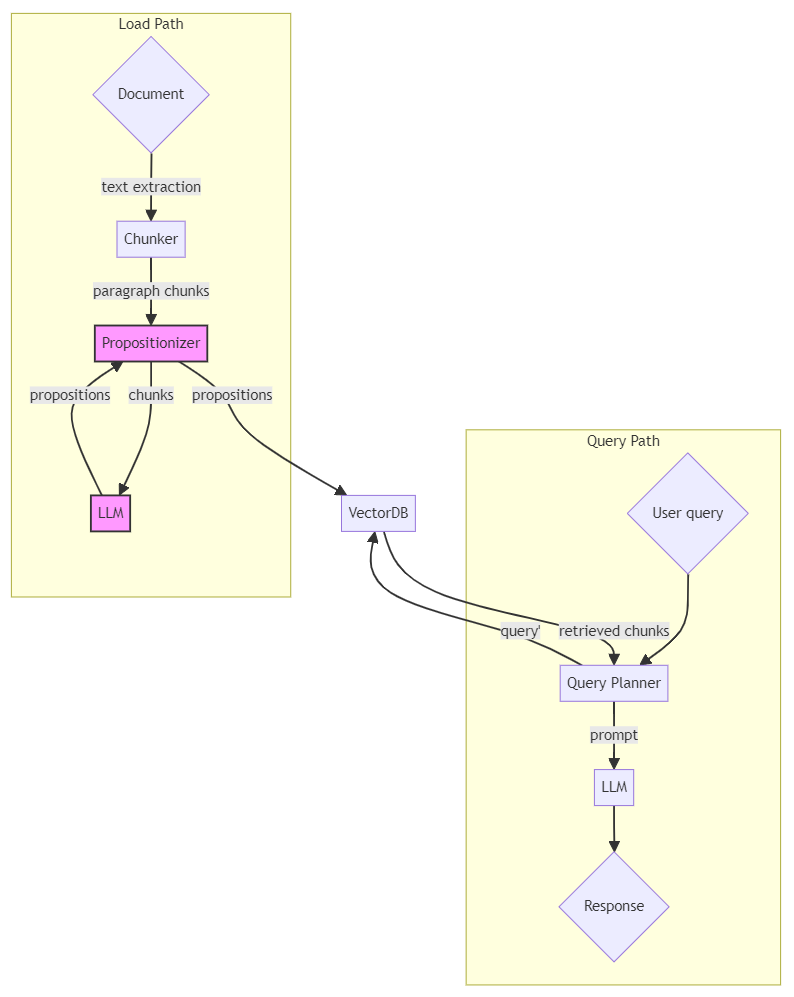
Propositionizer-enhanced RAG architecture.
To incorporate propositional chunking in your RAG pipeline, you need an additional load-side component: the propositionizer. And core to the functioning of a propositionizer is itself an AI model, which may be a LLM. The propositionizer works by iteratively building chunks with the help of a LLM or specialized model. The process is as follows:
- Start with a syntactic chunking iteration. Paragraph-based would be a good choice for this step.
- For each paragraph, use a LLM or equivalent model to generate standalone statements (propositions) using the chunked text with additional context derived from the surrounding text, utilizing the nested hierarchy of headings and subheadings where available.
- Remove redundant or duplicate propositions.
- Load the generated propositions into the vector database, instead of the original source document.
- Now on the query side of the pipeline, we will be retrieving a propositionized view of the original source document, and incorporating propositions into the complete query presented to the LLM.
But why do we need to do this as a discrete load-time step? If the heavy lifting is being potentially done by a LLM anyway, why not just leave it to the query-side LLM, perhaps with some appropriate chain-of-thought prompt engineering? The answer lies in economics, which we will get into in the next section.
Costs and benefits of propositional chunking
1 Unit economics of RAG chatbot-like applications
RAG pipelines can be thought of as two-sided machines; there is a load-path, and a query-path. However, in terms of usage, the two sides are not generally expected to be in balance because the frequency of document load should be far lower than the frequency of queries.
Projects that produce an attractive ROI will tend to exhibit asymmetry in load-side vs query-side activity because queries are what produce values for users, and if we want to amortize load-side costs through query-driven value, the most likely way to achieve that is to have more valuable queries. An information service that serves no reads is as useful as a ship in harbour.
The emphasis on valuable is key. Our thesis is that propositional chunking improves the economic viability of RAG-intensive applications by providing sustainable quality, leading to sustained usage.
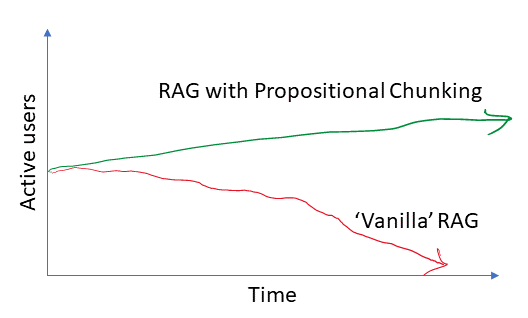
Our thesis is that propositional chunking will make a RAG project more successful by consistently delivering more value to users, thus improving user retention.
What would we have to do to drag the red line up? The naive approach would be to increase the size of chunks, therefore including more context in prompts. Hopefully with more context the LLM can do a better job of information retrieval, at the cost of increased query-time token consumption.
This also speaks to why propositional chunking is done at load-time rather than query-time. If we aim to build applications that serve many queries, taking costs out of the high-frequency query path is desirable. If we wanted to enable propositional chunking on the query path, we will need to include very large amounts of context to be able to propositionize effectively, thus hurting unit economics even more by increasing query-side token consumption.
2 Load-time costs introduced by propositional chunking
Let’s address the elephant in the room: propositional chunking adds a layer of processing and cost on the load-side. Especially when used alongside a powerful LLM like GPT-4, the costs can be significant.
However, one could consider fine-tuning a smaller, specialized model solely for the task of propositional chunking. While this involves an initial investment, the long-term benefits are significant in reduced computational load. A relatively small model can be trained efficiently from a well-chosen set of examples ultimately translating into cost savings. This is an area we are actively investigating.
3 Query performance improvement
The primary motivation for propositional chunking is better responses to queries. We already shared top-line benchmarking numbers at the top of this post, but now that we’ve seen how propositional chunking works, let’s see the results again.
Proposition-based retrieval consistently performs well for information retrieval and question-answering tasks. Recall@k is the percentage of questions for which the correct answer is found within the top-k retrieved passages, while EM@100 (Exact Match at rank 100) is the percentage of responses matching ground truth when evaluating only the top 100 retrievals. Figure source: Chen et al.
Research by Chen et al. provides compelling evidence for propositional chunking’s effectiveness within open-domain question-answering (QA) systems. Their study demonstrated that proposition-level retrieval significantly outperforms traditional sentence and passage-based approaches across multiple QA datasets. Key findings included enhanced precision, specificity, and improved top-5 and top-20 context recall metrics, even for less common entities. This highlights both the efficiency and adaptability gains offered by propositional chunking.
We’ll soon share a follow-up post with a practical experiment showcasing the benefits of propositional chunking. You’ll see firsthand how an LLM performs using standard chunking methods versus a propositional approach. In addition, we have a draft going deeper into the details of how a propositionizer works, and details on our methodology for performance evaluation.
Don’t miss these updates, please subscribe to hear about future publications.
4 Protecting your data moat
The true cost of a poorly performing RAG pipeline extends beyond cost of compute and storage. Inaccurate or irrelevant results erode the value of your data advantage. Propositional chunking ensures maximum precision and relevance, enhancing user trust and retention, and consequently safeguarding the competitive edge your data provides.
The future of data processing and RAG pipelines
Our view is that as user queries grow in complexity, and the scope of data requirements expands, the limitations of syntax-based chunking will become increasingly apparent. Traditional methods that focus purely on the structure of data, without considering its meaning, will fail to keep pace with the nuanced demands of modern information retrieval, and ultimately lead to projects which fail to reach production-grade quality, or fail to live up to expectations post-launch. The effectiveness of chunking is now defined by its semantic intelligence – the ability to discern and preserve the thematic continuity of text segments.
Furthermore, we envision the evolution of data masking beyond simple pattern-based detection and redaction to encompass query-time role-based view constraints like access rights, and flexible approaches that protect sensitive data like PII while maintaining sufficient semantic structure to enable analytical use cases. This evolution is not just a matter of compliance but of maintaining performance while ensuring privacy by design, as a source of operational advantage.
Say we’ve preprocessed - or compiled - our source data for optimal LLM query composition, and we’ve instrumented our pipeline to dynamically augment retrievals for operational purposes, what then? Is that the end of the road for RAG innovation, and is the rest largely in the hands of those driving improvements in foundation models?
1 Agentic RAG
Anyone who has experimented with self-prompting agents (like BabyAGI, AutoGPT, etc) has very likely received at least one email from OpenAI titled “OpenAI API - Soft Limit Notice” only to observe that the model has gone down a completely irrelevant rabbit hole or is going in circles unproductively.
But for those who persevere, it’s hard to top the excitement when the model successfully addresses the right question in a way that is surprising, but logical in hindsight. A lot of the promise of AI lies in making these occurrences more frequent, though the authors suspect they may personally never be any less exciting.
The emergence of agentic systems within Retrieval-Augmented Generation (RAG) pipelines are characterized by their proactive and self-regulating nature. Agentic RAG systems embody advanced artificial intelligence capabilities, enabling them to understand the intent behind queries, the semantic structure of the data, and the appropriate level of data masking required.
2 Constitution-Based Access Control
Moreover, we envision constitutional access control within these systems will ensure that retrieval and synthesis of information adhere to governance policy without relying on unmaintainable attribute-based approaches, or non-scalable role-based approaches. Agentic RAG systems, equipped with constitution access control, can autonomously regulate the flow of data, providing responses that are not only contextually rich and semantically coherent but also privacy-aware and compliant with policy frameworks.
In essence, the future of data preprocessing lies in the fusion of semantic understanding, intelligent data masking or augmentation, and adaptive but consistent policy grounded access control. This triad forms the backbone of a new generation of RAG systems, which are set to redefine the boundaries of what is possible in the realm of data processing and knowledge retrieval.
Don’t forget to like and subscribe
We aim to maintain a balance between experimentation and client work, but we are also committed to knowledge sharing. Current blog post drafts include:
- A deep dive into propositional chunking, following up on this post, including evaluation methodology
- A review of DSPy
- Thoughts on infinite context windows
And there’s more in the pipeline. If this content is interesting to you please subscribe so you won’t miss updates.
There is a great big Agentic RAG mind-map that we are systematically exploring, and if you would like to join us, please don’t hesitate to say [email protected].
References
- Tong Chen, Hongwei Wang, Sihao Chen, Wenhao Yu, Kaixin Ma, Xinran Zhao, Hongming Zhang, Dong Yu, Dense X Retrieval: What Retrieval Granularity Should We Use? (last revised 12 Dec 2023)
- Gautier Izacard, Mathilde Caron, Lucas Hosseini, Sebastian Riedel, Piotr Bojanowski, Armand Joulin, Edouard Grave, Unsupervised Dense Information Retrieval with Contrastive Learning (last revised 29 Aug 2022)
- Jianmo Ni, Chen Qu, Jing Lu, Zhuyun Dai, Gustavo Hernández Ábrego, Ji Ma, Vincent Y. Zhao, Yi Luan, Keith B. Hall, Ming-Wei Chang, Yinfei Yang, Large Dual Encoders Are Generalizable Retrievers (submitted on 15 Dec 2021)