Effective RAG evaluation: integrated metrics are all you need
Understanding and Addressing Common Challenges in Evaluation of Retrieval-Augmented Generation Systems

Retrieval-Augmented Generation (RAG) pipelines have revolutionised how we integrate custom data with large language models (LLMs), unlocking new possibilities in AI applications. However, evaluating the effectiveness of these pipelines has presented a major challenge for most real-world applications. In this post, we’ll look deeper into the pain points of RAG pipeline evaluation and explore strategies to overcome them.
The Complex Landscape of RAG Evaluation
Evaluating a RAG pipeline isn’t just about measuring its output quality. Proper evaluation requires an understanding of the intricate interplay between retrieval models and generation models, each with their own objectives and performance metrics. Misalignments between these components can lead to subtle yet significant issues that traditional evaluation metrics might overlook.
Let’s unpack these challenges step by step.
1 Misalignment Between Retrieval and Generation Models
Before exploring how retrieval and generation interplay, it’s important to recognise that their distinct optimisation goals can quietly push the overall system toward nuanced but meaningful misalignments.
1.1 Diverging Goals: Relevance vs. Fluency and Factuality
At the heart of a RAG pipeline lies a fundamental tension:
- Retrieval Models aim for relevance, optimising for precision and recall to fetch documents that match the query.
- Generation Models focus on fluency, coherence, and factual correctness, crafting responses that are not only accurate but also linguistically natural.
This divergence creates specific misalignments between retrieval accuracy and generation quality. A retrieval model might consider its job done by providing documents that are relevant in isolation, but these documents might lack the specificity or context needed for the generation model to produce a precise answer.
1.2 The Relevance vs. Utility Gap
Consider a scenario where a user asks: “What’s the impact of quantum computing on cryptography?”
The retrieval model might fetch documents broadly related to quantum computing and cryptography. However, if these documents don’t address the intersection of the two topics specifically, the generation model might struggle, potentially leading to:
- Hallucinations: The model fabricates plausible-sounding but incorrect information.
- Factual Inaccuracies: The response includes outdated or irrelevant facts.
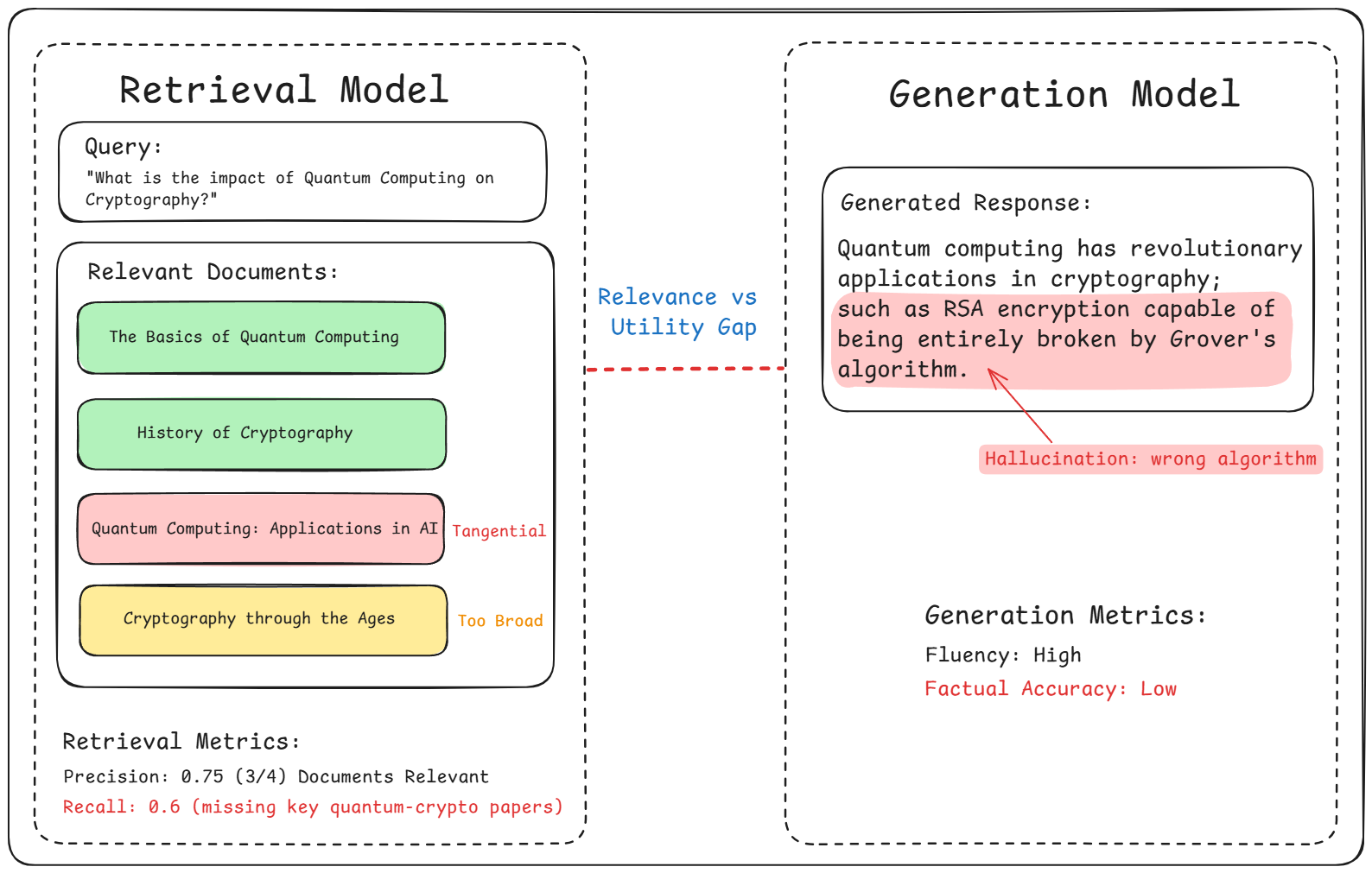
The retrieval model fetches documents with varying levels of relevance and specificity, but the generation model produces a response containing hallucinations due to a misalignment between retrieved content and the query.
1.3 Compensatory Mechanisms and Error Masking
Generation models are designed to produce coherent text, even when provided with suboptimal inputs. They might “fill in the gaps” when the retrieved documents lack necessary details. While this can make the system seem robust, it masks underlying retrieval errors, making it difficult to diagnose issues.
1.4 Error Masking and Creativity Trade-Offs
This adaptability leads to a trade-off:
- Benefit: The system appears to handle a wide range of inputs gracefully.
- Drawback: Latent retrieval issues are obscured, and the generation model’s “creativity” can introduce inaccuracies.
2 Noise Amplification and the Challenge of Hallucinations
The interplay between ambiguous queries and suboptimal retrieval often leads to cascading performance issues, where irrelevant or loosely connected content exacerbates errors and compromises the overall reliability of the system. Research by Wu et al. (2024) introduces a “Pandora’s Box” effect of harmful noise, illustrating how the presence of counterfactual, supportive, or semantically aligned yet non-answer-bearing information alongside the intended correct context can erode performance across multiple question-answering datasets. In other words, even contextually plausible but extraneous details can nudge the generation model toward plausible-sounding inaccuracies. Given that these errors often manifest as the model generating plausible but incorrect statements, it is reasonable to hypothesise that similar mechanisms likely drive increased rates of hallucination.
2.1 Amplification of Noise Through Irrelevant Retrievals
Such irrelevant or loosely related documents to the query retrieved by the system introduce noise into the generation process. This noise doesn’t just dilute the quality of the response—it can actively mislead the generation model.
2.2 Ambiguity from Noisy Inputs
Noisy inputs make it challenging to determine:
- Is the hallucination due to faulty retrieval?
- Is the generation model misinterpreting accurate but irrelevant information?
This ambiguity complicates troubleshooting and improvement efforts. Moreover, the vulnerability of RAG systems to even minor noise, as demonstrated by Cho et al. (2024), underscores how small textual perturbations in otherwise relevant documents can drastically reduce the accuracy of generated answers. These subtle disruptions complicate the system’s ability to distinguish between genuinely useful information and misleading signals, blurring the line between retrieval and generation errors.
2.3 Diagnostic Challenges Due to Ambiguity from Noise
Noise not only affects output quality but also complicates troubleshooting by creating ambiguity in diagnosing the root causes of hallucinations. When outputs are flawed, it becomes challenging to determine whether the issue stems from retrieval deficiencies—such as irrelevant or misleading documents—or from the generation model misprocessing the inputs. This challenge in diagnosis hinders effective error correction and model improvement, as efforts may be misdirected without clear identification of the underlying problems.
2.4 Propagation of Retrieval Errors into Generation
Errors at the retrieval stage do not remain isolated; they propagate through the pipeline, affecting the quality of the generative outputs. Missing critical documents lead to incomplete information for the generation model, resulting in vague or partially correct responses. Redundant retrievals can overwhelm the generation model with repetitive or incongruent information, causing it to produce incoherent or unfocused outputs. For instance, if essential context is omitted during retrieval, the generation model lacks the necessary grounding to produce accurate answers, increasing the risk of inaccuracies and hallucinations.
2.5 Subtle Semantic Drift
Over time, unresolved misalignments and lingering noise gradually undermine reliability. Minor misalignments in retrieved content can erode system performance, especially when retrieval prioritises broad relevance over precise, query-specific matches. These misalignments occur when retrieval engines surface documents with general thematic overlap rather than precise alignment—for example, returning documents on “renewable energy trends” in response to a query about “solar energy growth in 2023”—and when fixed-granularity methods may exclude critical details, creating gaps in the grounding context. These subtle factual deviations, while seemingly negligible in isolation, accumulate over iterative interactions because each misalignment doesn’t just affect a single response; it influences subsequent interactions by providing a flawed foundation for future queries. This creates a feedback loop where errors compound over time—initial inaccuracies lead to increasingly distorted responses, further exacerbated by misinterpreted inputs and contextual degradation as errors propagate through the RAG pipeline. Multi-turn, exploratory, or high-context queries are especially vulnerable, and issues including retrieval ambiguity or redundant and conflicting signals amplify inaccuracies, leading to a significant divergence from the original factual or contextual basis over time.
2.6 Amplification of Ambiguous and Conflicting Signals
As subtle drifts and unresolved ambiguities accumulate, irrelevant retrievals introduce not only noise but also ambiguous or conflicting information that complicates the generation process. The presence of conflicting data from disparate sources can confuse the generation model, leading to outputs that are inconsistent or contradictory. For instance, if the retrieval includes documents with opposing viewpoints or outdated information, the generation model may struggle to produce a coherent response, increasing the likelihood of errors and reducing the system’s reliability.
Query: “What are the current global strategies to combat climate change?”
Retrieved Content:
- Document A: A recent report advocating for renewable energy expansion as a primary strategy, emphasizing solar and wind adoption (e.g., a 2023 UN climate action report).
- Document B: An older, outdated report from 2010 downplaying renewable energy’s role and instead prioritizing geoengineering solutions like carbon capture.
- Document C: A controversial opinion piece arguing against climate change mitigation, citing economic costs as prohibitive and questioning climate science consensus.
Generation Model’s Output: Faced with conflicting signals—one advocating renewables, another focusing on geoengineering, and yet another denying the urgency of climate change—the generation model attempts to reconcile the inputs. This leads to a response such as:
“Current global strategies to combat climate change include expanding renewable energy adoption and exploring geoengineering solutions, though the efficacy and urgency of these approaches remain debated due to economic concerns and scientific uncertainties.”
While coherent on the surface, this response is inconsistent and misleading:
- It conflates outdated geoengineering emphasis with modern strategies.
- It amplifies conflicting viewpoints, misrepresenting the scientific consensus on climate change.
3 Metric Misalignment and Evaluation Challenges
Beyond content-level discrepancies, the very methods we use to measure performance can obscure key issues, preventing us from fully understanding where the pipeline truly excels—and where it falls short.
3.1 Disjointed Metrics: Coverage vs. Linguistic Quality
Traditional evaluation metrics exacerbate the problem:
- Retrieval Metrics: Focus on coverage (e.g., precision, recall), assessing how well documents match the query.
- Generation Metrics: Assess linguistic quality (e.g., BLEU score, ROUGE), focusing on fluency and coherence.
Evaluation metrics often treat the retriever and generator as separate entities, without considering their interaction within the RAG system. Metrics like BLEU and ROUGE are less effective for evaluating extended, detailed answers, as they don’t capture semantic richness or factual accuracy. This siloed approach misses the nuances of how retrieval and generation interact within a RAG pipeline.
3.2 Evaluation Drift
Over-reliance on these traditional metrics fails to capture:
- Pipeline Inefficiencies: Misalignments between retrieval and generation stages.
- Task-Specific Nuances: Challenges unique to RAG tasks like multi-hop reasoning or attribution.
3.3 End-to-End “Black Box” Metrics Obscuring Pipeline Errors
End-to-end evaluation metrics provide an overall performance snapshot but often fail to disentangle errors originating from different components within the RAG pipeline. This obscures the ability to target specific issues for improvement. Without metrics that attribute errors to either the retrieval or generation stages, diagnosing the root causes of performance degradation becomes challenging. For example, a decline in overall accuracy might result from poor document retrieval, suboptimal generation, or both, but end-to-end metrics alone cannot reveal this distinction.
3.4 The Need for a Holistic Evaluation Framework
To truly assess a RAG pipeline’s performance, we need metrics that:
- Bridge Components: Evaluate how retrieval quality impacts generation and vice versa.
- Measure Groundedness: Ensure that generated responses are not only fluent but also based on the retrieved evidence, ensuring both relevance and factual accuracy.
4 The Impact of Query Ambiguity
Turning our attention to user inputs, the phrasing and clarity of queries play a significant role in shaping retrieval and generation outcomes, often in ways that are difficult to anticipate.
4.1 Vague or Underspecified Queries
When users provide ambiguous queries, the retrieval model struggles to fetch relevant documents, leading to:
- Tangential Retrievals: Documents that are related to the query terms but miss the user’s intent.
- Distracting Content: Irrelevant information that the generation model might inappropriately incorporate.
The generation model may struggle to produce accurate responses due to the lack of clear guidance, increasing the likelihood of errors or irrelevant content.
4.2 Noise and Robustness
Ambiguous queries introduce noise that challenges the system’s robustness. The generation model may:
- Misinterpret Inputs: Place undue emphasis on irrelevant details.
- Produce Inaccurate Responses: Due to lack of specific guidance.
4.3 Granularity Mismatch
The level at which retrieval operates—be it document, passage, or sentence—affects performance:
- Too Broad: Retrieving whole documents may include substantial irrelevant information.
- Too Narrow: Retrieving individual sentences might not provide sufficient context for accurate generation.
4.4 Balancing Context Length and Relevance
Trade-Offs:
- Including More Context: Providing additional information can improve answer completeness but may introduce noise that confuses the generation model.
- Avoiding Overload: Excessive context can overwhelm the model and increase computational costs without guaranteeing better responses.
Ambiguity in queries underscores the importance of balancing retrieval granularity and context specificity, as both overgeneralized and overly narrow retrieval approaches significantly impact the system’s ability to deliver accurate, coherent, and contextually grounded responses.
| Too Broad | Too Narrow | |
|---|---|---|
| Including More Context | * Whole documents provide additional information but may contain irrelevant details, increasing noise. * This can confuse the generator, making it harder to extract focused, accurate answers. |
* Narrow retrieval at sentence level may fail to include critical, broader context necessary for accurate generation. * This limits the model’s ability to synthesise comprehensive responses. |
| Avoiding Overload | * Document-level granularity avoids excessive narrow retrievals but increases computational overhead without guaranteeing better precision. * Overwhelming models with irrelevant sections can degrade response quality. |
* Sentence-level retrieval reduces noise and computational costs but may omit valuable contextual cues needed for nuanced or complex queries. * Leads to incomplete or oversimplified generation outputs. |
Adaptive granularity strategies are essential to balance context and specificity. Assessing how effectively the system manages this balance is important for optimisation but is difficult with current evaluation methods.
Strategies to Mitigate Evaluation Pitfalls
While the challenges are significant, they’re not insurmountable. Here are some strategies to address them:
-
Aligning Retrieval and Generation Objectives:
- Joint Optimization: Develop models that consider both retrieval relevance and generation utility during training.
- Contextual Retrieval: Enhance retrieval models to understand the generation model’s needs, fetching documents that are not just relevant but contextually rich.
-
Reducing Noise and Hallucinations:
- Filter Mechanisms: Implement pre-processing steps to remove irrelevant retrievals before they reach the generation model.
- Confidence Scoring: Assign confidence levels to retrieved documents, allowing the generation model to weigh inputs appropriately.
-
Developing Holistic Evaluation Metrics:
- Groundedness Measures: Create metrics that assess how well the generated output aligns with the retrieved evidence.
- End-to-End Evaluation: Use composite metrics that evaluate the pipeline as a whole rather than its individual components.
-
Handling Query Ambiguity:
- Query Clarification: Incorporate mechanisms to prompt users for clarification when queries are too vague.
- Adaptive Retrieval Granularity: Dynamically adjust the retrieval granularity based on the query’s specificity.
Addressing Challenges in Evaluation Metric Design and Implementation
A concern is that implementing comprehensive evaluation metrics demands significant resources and may not be practical for all organisations. Resource considerations are valid when evaluating Retrieval-Augmented Generation (RAG) systems, particularly due to the substantial computational, financial, and infrastructural demands involved. Implementing effective evaluation metrics requires significant resources, including time, computational power, and financial investment. For instance, evaluating dense vector retrieval over billions of documents necessitates high-performance GPU clusters or API costs and expansive storage capacities. Additionally, preparing evaluation datasets often involves annotating retrieval outputs for relevance and verifying the factual accuracy of generated responses, further increasing resource allocation.
However, the long-term benefits of enhanced accuracy and increased user trust outweigh the initial investment. Adopting scalable approaches, such as prioritising critical components or high-impact use cases, allows for the incremental development of a comprehensive and manageable evaluation framework.
Some might argue that existing metrics are adequate when applied correctly, suggesting that any problems arise from improper use rather than flaws in the metrics themselves. While correct application is important, traditional metrics often overlook the complex interdependencies between retrieval and generation components in RAG pipelines. To genuinely understand and improve these systems, we need to develop or adopt metrics specifically designed to evaluate the combined performance of both components.
Conclusion
Evaluating RAG pipelines is a complex endeavour that requires a nuanced understanding of the interplay between retrieval and generation components. By acknowledging and addressing the pain points—misalignment of objectives, noise amplification, metric misalignments, and query ambiguity—we can build more robust, accurate, and reliable AI systems.
Looking Ahead
In future posts we’ll get into more sophisticated techniques, tools, and frameworks, as well as some case studies. Please subscribe so you won’t miss these.
For feedback or inquiries, please reach out at [email protected].
References
-
Es, S., James, J., Espinosa-Anke, L., & Schockaert, S. (2024). RAGAs: Automated Evaluation of Retrieval Augmented Generation.
-
Ru, D., Qiu, L., Hu, X., Zhang, T., Shi, P., Chang, S., Cheng, J., Wang, C., Sun, S., Li, H., Zhang, Z., Wang, B., Jiang, J., He, T., Wang, Z., Liu, P., Zhang, Y., & Zhang, Z. (2024). RAGChecker: A Fine-grained Framework for Diagnosing Retrieval-Augmented Generation.
-
Wu, J., Che, F., Zhang, C., Tao, J., Zhang, S., & Shao, P. (2024). Pandora’s box or Aladdin’s lamp: A comprehensive analysis revealing the role of RAG noise in large language models.
-
Cho, S., Jeong, S., Seo, J., Hwang, T., & Park, J. C. (2024). Typos that broke the RAG’s back: Genetic attack on RAG pipeline by simulating documents in the wild via low-level perturbations.