Topic Modeling: A Comparative Overview of BERTopic, LDA, and Beyond
Evaluating modern approaches to extracting themes from unstructured text

Hashtags were a defining innovation of Web 2.0; what started as a user-invented hack on Twitter in 2007 has become entrenched as an organizing tool in platforms like Instagram and TikTok, driving community curation and content discovery. This was “folksonomy” in action: bottom-up labeling that adapts faster than top-down taxonomies ever could. But with #AI, can we reinvent the concept of taxonomy to combine the “evolveability” of a bottom-up approach with the “systemizability” of a top-down approach? That is the promise of topic modeling.
The tweet that gave the world hashtags:
The first hashtag
Topic modeling use cases
Where there is unstructured text/content, topic modeling can be applied as a research tool, or to enable product features. Some common applications include:
-
Content discovery and navigation: Automatically group content (articles, communication messages including social media posts, transcribed audio/video, etc) by theme to enable automation or improve search and recommendations.
-
Trend and theme analysis: Track how discussion topics evolve over time — valuable for newsrooms, social platforms, and user research teams.
-
Information retrieval: Enable efficient search indexing (as a supplement to whole-document vectorisation) over large unstructured corpora like documentation, legal texts, or support logs.
-
Customer insight extraction: Summarize patterns in reviews, surveys, or tickets to surface emerging pain points or opportunities.
-
Tag suggestion and refinement: Automate and improve tag assignment, enhancing folksonomy-driven systems with greater consistency.
-
New corpus analysis: Generate an initial set of interpretable categories/tags for new or unlabeled datasets.
To enable these varied applications, a number of topic modelling approaches and tools exist, with different characteristics, driven by different requirements, though there are several requirements that would generally apply to all topic modeling approaches.
Topic modeling requirements
According to Abdelrazek et al (2023), several common criteria may be applied to evaluate topic modeling approaches in a general sense, ranging from metrics that represent the technical performance of a model, as well as practical factors:
-
Topic perplexity: Measures how well a model predicts the documents in a corpus based on learned topics. Lower perplexity typically indicates better predictive performance, but it may not correlate with topic interpretability in practice.
-
Topic coherence: Evaluates the semantic interpretability of individual topics, usually by assessing the similarity of the top-N words (e.g. top 10) within each topic. Coherence scores typically range from -1 to 1, with higher scores indicating more meaningful, human-interpretable topics.

-
Topic diversity: Quantifies how distinct the topics are from one another. It is defined as the proportion of unique words across all topics (ranges from 0 to 1). A higher value indicates more diverse topic representations.
-
Topic stability: Reflects how consistent the topic rankings are across different runs. Since topic modeling algorithms—especially probabilistic and neural variants—are non-deterministic, stability is often evaluated via metrics such as Jaccard similarity over top-k words, or Rank-Biased Overlap (RBO) across model runs.

-
Efficiency: Captures time and memory complexity, which become especially relevant when scaling to large corpora or deploying in constrained environments.
-
Flexibility: Although harder to quantify, flexibility refers to a model’s robustness across varying document lengths, domains, or languages. It reflects the ease with which a method can be adapted to different types of text corpora.
In addition to these general considerations, our specific use case has some additional constraints:
-
The model must handle medium- to long-form documents (e.g. blog posts and academic papers) without degrading performance. We don’t care about social media sized text.
-
It should be able to adapt to concept drift over time. For instance, topics initially focused on “Melbourne”, “Geelong”, and “Ballarat” might be grouped under a “Victoria” topic, but later adjusted to a broader “Australia” topic as articles about “Sydney” and “Brisbane” are added.
-
The model must be capable of operating in cold-start scenarios, where no pre-existing corpus is available at the outset. We may consider a hybrid approach (e.g. cold start routes to system A, and once corpus size exceeds some threshold switch to system B).
Abdelrazek et al. (2023) provide a comprehensive analysis of various factors to consider for effective evaluation, see Figure 1.
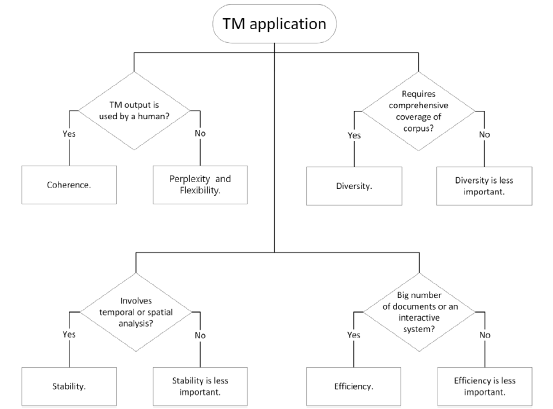
Fig 2: Factors worth considering for evaluation of topic modeling applications, Abdelrazek et al. [1]
From this analysis, several key requirements stand out:
-
Generate topics that are interpretable for customers: The topics produced must be human-readable and meaningful, ensuring that the output is actionable for end users.
-
Provide comprehensive coverage of the corpus: The model should be able to capture a wide range of themes present in the text corpus, without missing key concepts.
-
Incorporate temporal analysis: The model should be capable of tracking how topics evolve over time, adapting to shifts in content focus.
-
Support interactive exploration: The solution should allow for user interaction, enabling users to explore and refine topics dynamically.
Conventionally, the most important criteria for topic modeling solutions are coherence, diversity, stability, and efficiency. Of course the criteria we will prioritize for evaluation will depend on the specific needs of our use case, but these key general criteria will be useful to bear in mind.
Alternative topic modeling solutions
Topic modeling solutions can be broadly categorized into four types: algebraic, fuzzy, probabilistic, and neural (as illustrated in Figure 2). In this article, we will focus on probabilistic and neural topic models, as these approaches have seen continuous development and widespread adoption at the time of writing.

Figure 3: Topic model categorization (from [1]).
1 Probabilistic topic modeling approaches
Probabilistic topic models capture the probabilistic relationships between entities in a corpus. These models often employ directed acyclic graphs (DAGs) to map relationships, and they are part of the broader Bayesian modeling family. In these models, the nodes can represent either observed variables (e.g., words) or hidden variables (e.g., topic distributions), while the edges indicate the probabilistic dependencies between them.
Two prominent examples of probabilistic topic models are Latent Dirichlet Allocation (LDA) and LDA2vec, an extension of LDA.
1.1 Latent Dirichlet Allocation (LDA)
Latent Dirichlet Allocation (LDA), introduced by Blei et al. (2003), assumes that documents are mixtures of a small number of pre-defined topics. The model works by inferring these topics from the observed words in the corpus. It treats documents as being produced by a random sampling process, where each document is associated with a mixture of topics. The task of LDA is to reverse-engineer this process to uncover the topics that best explain the observed word distributions in the documents..
LDA treats the corpus as a bag-of-words, meaning it ignores word order and context, instead focusing on word frequency and co-occurrence patterns (i.e., how often words appear together within a document). Specifically, LDA assumes:
-
Each document is a mixture of topics.
-
Each topic has a fixed vocabulary, with each word having a certain probability of occurring in that topic.
-
For each word in a document, a topic is randomly selected, and a word is sampled from that topic’s vocabulary.
The topic distribution in LDA follows a Dirichlet distribution, modeling the sparsity of topic distributions across documents. This allows LDA to capture the idea that most documents discuss only a subset of topics. LDA typically uses Gibbs sampling for topic assignment, with variational inference (or Markov Chain Monte Carlo) used for efficient computation, especially when the corpus has a large number of topics.
Infobox: What is the Dirichlet distribution?
The Dirichlet distribution is a way to generate probability distributions over categories, like deciding how much weight to give to each topic in a document. It’s often used when we need to model uncertainty over proportions that must add up to 1.
In topic modeling (e.g. LDA), Dirichlet priors help ensure that:
-
Each document emphasizes just a few topics (not all at once), and
-
Each topic favors a few distinctive words (not the whole vocabulary).
This leads to sparse, interpretable topics that reflect how humans typically write: focused, not scattered.
The Dirichlet distribution is also used in Naive Bayes spam filters.
1.1.1 Strengths of LDA
-
Simplicity and Interpretability: LDA is relatively easy to implement and understand, and the results are interpretable, or at least explainable.
-
Language-agnostic: Since LDA focuses on word probabilities rather than context, it is especially useful in low-resource environments and can be applied to corpora in languages other than English.
-
Stability: LDA’s results are often more stable compared to some modern neural topic models, especially those based on variational autoencoders .
1.1.2 Drawbacks of LDA
-
Context-insensitivity: As a probabilistic model, LDA cannot differentiate between words with different meanings in different contexts. For example, it would treat “windows” in a house and “windows” as an operating system in the same way, which limits its semantic understanding.
-
Scalability: If specialised AI acceleration hardware (i.e. GPUs, NPUs) are available, LDA implementations may not be readily able to leverage these capabilities, so LDA might be a more attractive approach in environments where access to such compute resources are not assured anyway. But where access to this hardware is assured, and utilisation is desirable (e.g. on AWS SageMaker NTM hardware), then it may be advisable to avoid LDA and favor neural approaches.
1.2 LDA2vec
LDA2vec, developed by Moody (2016), builds on the foundation of LDA by incorporating word embeddings. It combines the Dirichlet distribution for document-level vectors with word vectors generated through Skipgram Negative Sampling Loss (SNGS). This combination enables LDA2vec to create meaningful vector representations for both words and documents.
Infobox: What is Skip-gram Negative Sampling?
Skip-gram with Negative Sampling (SGNS) is a training method used to learn word embeddings — vector representations that capture a word’s meaning based on its context. It powers the popular word2vec model.
The core idea: given a word, the model tries to predict nearby words (the “context”), while also learning to ignore randomly selected “negative” words that don’t appear nearby. This contrast helps the model learn which words tend to occur together, resulting in embeddings where semantically similar words are close in vector space.
In topic modeling (e.g. LDA2vec), SGNS enables the model to capture semantic relationships, not just word frequency — so that terms like “Australia” and “Canberra” naturally cluster together.
SGNS is widely used in word2vec and similar models, but most modern embedding models (like BERT or SBERT) use different training objectives based on masked language modeling or contrastive learning.
The key difference between LDA2vec and traditional LDA is its use of word and document vectorization. While LDA still relies on a bag-of-words approach, LDA2vec can understand the semantic relationships between words in different contexts. For example, the vector representation of “Australia” + “capital” would be closer to “Canberra” than to other words like “Sydney.”
LDA2vec also provides a more direct way to retrieve topics associated with any given document, making topic exploration more convenient than in traditional LDA.
1.2.1 Strengths of LDA2vec
-
Contextual Understanding: By incorporating word embeddings, LDA2vec better understands the meaning of words in different contexts, leading to more accurate and interpretable topics.
-
Ease of Analysis: LDA2vec allows for easier topic analysis by providing a clear mapping of topics to individual documents.
1.2.2 Drawbacks of LDA2vec
- Obsolescence: Although LDA2vec is newer than LDA, its main open source implementation has not been maintained (e.g. Python 3 support has languished in an unmerged PR). The idea is appealing, but the lack of a ready-to-use well supported package makes it an expensive proposition, and therefore on the surface it would appear that the overall approach may be obsolete in favor of more holistic neural approaches. We shall see if this approach may be worth reviving in a hybrid sense, perhaps with LDA-at-the-edge and neural inference in the cloud.
2 Neural topic modeling approaches
With the explosive growth of neural network based approaches at the time of writing, especially large language models (LLMs), neural topic models have gained increasing traction. These models typically rely on embedding techniques (or LLMs), benefiting from robust inference hardware (e.g. GPUs/NPUs) which may be on-device or on-cloud.
Several packages are available to enable rapid application development, and of these, at the time of writing, one of the most popular packages is BERTopic.
2.1 BERTopic
https://maartengr.github.io/BERTopic/index.html
BERTopic, proposed by Grootendoost (2022), converts documents into embeddings using the SBERT architecture from the Transformers library. It clusters semantically similar documents and leverages UMAP for dimensionality reduction and HDBSCAN for clustering. TF-IDF is used to identify important words within topics, aiding in their representation.
Infobox: What are UMAP and HDBSCAN?
In neural topic models like BERTopic, raw document embeddings are high-dimensional — too complex to cluster directly. That’s where UMAP and HDBSCAN come in.
-
UMAP (Uniform Manifold Approximation and Projection)
A technique for dimensionality reduction. It takes high-dimensional embeddings (like 384- or 768-dimensional vectors from SBERT) and projects them down to 2–10 dimensions, while trying to preserve the original structure. This makes downstream clustering faster and more meaningful. -
HDBSCAN (Hierarchical Density-Based Spatial Clustering of Applications with Noise)
A clustering algorithm that groups together points with similar local densities. Unlike K-means, it doesn’t require specifying the number of clusters in advance and can handle clusters of varying shapes and sizes. It also identifies “noise” — documents that don’t cleanly fit into any topic.
Together, UMAP and HDBSCAN help models like BERTopic group similar documents into coherent topics — even in messy, real-world corpora.
The main advantage of BERTopic is its ability to capture contextual meanings by using embeddings, unlike probabilistic bag-of-words models. Additionally, BERTopic normalizes TF-IDF using L1-norm, enabling it to track concept drift over time as topics evolve. BERTopic is continually developed, allowing the addition of new features like LLM integration and multimodal capabilities, making it one of the most popular topic modeling solutions today.
2.1.1 Strengths of BERTopic
-
Contextual Understanding: Embeddings enable the model to discern the meaning of words in different contexts, improving topic quality.
-
Topic Evolution: The L1-normalized TF-IDF helps BERTopic track concept drift over time.
-
Flexibility: Designed as an extendible and composable stack, enabling continuous evolution.
2.1.2 Drawbacks of BERTopic
-
Single Topic Assumption: BERTopic assumes each document contains only one topic, limiting flexibility.
-
Context-insensitivity: Like traditional models, it cannot always differentiate between topics with similar vocabulary but different meanings.
-
High Computational Costs: Requires strong hardware for running on large datasets, making it more resource-intensive than probabilistic models.
2.2 BunkaTopics
https://charlesdedampierre.github.io/BunkaTopics/index.html
BunkaTopics, developed by Dampierre (2024), is a Python package that facilitates all steps of topic modeling: data cleaning, model inference, and visualization. It uses the SBERT architecture for text embeddings and UMAP for dimensionality reduction, but offers t-SNE as an alternative. Unlike BERTopic, BunkaTopics uses the K-means algorithm for clustering and has its own mechanism for reranking topics based on terms.
BunkaTopics shares many of BERTopic’s strengths, such as understanding semantic relationships and offering topic visualization for user validation. However, like BERTopic, it assumes only one topic per document, a limitation for more complex analyses.
2.2.1 Strengths of BunkaTopics
-
Collaborative Analysis: Supports data cleaning and topic selection by users, thus has direct support for learning from user feedback and preferences.
-
Topic Visualization: Good support out of the box for visualisation of topic groupings, so is well suited to more analytical topic research tasks.
2.2.2 Drawbacks of BunkaTopics
-
Single Topic Per Document: Like BERTopic, it limits each document to a single topic, which can be restrictive.
-
K-means Limitation: K-means is a hard clustering algorithm, which prevents the model from assigning multiple topics to a single document.
2.3 FASTopic
https://github.com/BobXWu/FASTopic
FASTopic, proposed by Wu et al. (2024), uses BERT and SBERT embeddings for document analysis but diverges from clustering approaches. Instead, it calculates dual semantic relations between documents and topics, as well as between topics and words. Transport plans and the Sinkhorn algorithm are used to compare distributions and account for semantic distances.
The main advantage of FASTopic is its computational efficiency. It is faster than BERTopic across all dataset sizes and significantly outperforms LDA in runtime. Additionally, FASTopic provides better topic coherence and stability.
2.3.1 Strengths of FASTopic:
-
Efficiency: Faster than BERTopic, especially with large datasets.
-
Higher Quality Topics: Delivers more stable and coherent topics compared to alternatives.
2.3.2 Drawbacks of FASTopic:
- Lack of Document-level Topic Retrieval: FASTopic analyzes entire datasets but does not provide topic information for individual documents, which is a limitation for use cases that require topic analysis at the document level.

Figure 3: Comparison of performance between FASTopic and other popular solutions for topic modeling (LDA, BERTopic, and more) [9].
2.4 QuaIIT
QuaIIT, proposed by Kapoor et al. (2024), was developed by Amazon to analyze qualitative responses in talent management. The model integrates LLMs directly into the topic extraction pipeline, starting with key-phrase extraction using an LLM, followed by embeddings with the Amazon Titan model. Coherence scores are used to flag and remove irrelevant content before K-means clustering identifies main and sub-topics.
QuaIIT offers higher topic coherence and topic diversity compared to LDA and BERTopic, with 35% of topics being consistent across all evaluators, compared to 20% for LDA and BERTopic.
2.4.1 Strengths of QuaIIT
-
Topic Coherence and Diversity: Outperforms LDA and BERTopic in both coherence and diversity, especially with a larger number of topics.
-
Multiple Topics Per Document: Unlike BERTopic, QuaIIT can return multiple topics from a single document.
-
Better Interpretability: Results are easier to classify and interpret, with higher agreement across evaluators.
2.4.2 Drawbacks of QuaIIT
-
Longer Runtime: Takes 2-3 hours to run, compared to 30 minutes for BERTopic (from [2]) , largely due to the use of K-means.
-
Topic Accuracy: While its topics are more interpretable, topic accuracy and handling of complex data patterns could still be improved.
Topic closed
Topic modeling has come a long way — from interpretable probabilistic models like LDA to powerful neural solutions like BERTopic, FASTopic, and QuaIIT. Each approach offers tradeoffs across axes like coherence, diversity, flexibility, and runtime performance. Choosing the right tool isn’t just about benchmark scores or architecture — it depends on your specific goals, data characteristics, and operational constraints. Whether you’re building for exploration, search, or insight generation, understanding these models’ strengths and limitations is key to making topic modeling work for you.
References
(1): Topic modeling algorithms and applications: A survey; Aly Abdelrazek, Yomna Eid, Eman Gawish, Walaa Medhat, Ahmed Hassan (Information Systems 112 (2023)): https://www.sciencedirect.com/science/article/abs/pii/S0306437922001090
(2): Qualitative Insights Tool (QualIT): LLM Enhanced Topic Modeling: Satya Kapoor, Alex Gil, Sreyoshi Bhaduri, Anshul Mittal, Rutu Mulkar: https://arxiv.org/pdf/2409.15626
(3): Latent Dirichlet Allocation: David M. Blei, Andrew Y. Ng, Michael I. Jordan
(4): https://www.ibm.com/think/topics/latentdirichlet-allocation
(5): https://docs.aws.amazon.com/sagemaker/latest/dg/lda.html
(6) Are Neural Topic Models Broken?: Alexander Hoyle, Pranav Goel, Rupak Sarkar, Philip Resnik.
(7) Mixing Dirichlet Topic Models and Word Embeddings to Make lda2vec, Christopher Moody: https://arxiv.org/abs/1605.02019
(8) BunkaTopics, Charles de Dampierre: https://charlesdedampierre.github.io/BunkaTopics/
(9) FASTopic: Pretrained Transformer is a Fast, Adaptive, Stable, and Transferable Topic Model: Xiaobao Wu, Thong Nguyen, Delvin Ce Zhang, William Yang Wang, Anh Tuan Luu: https://arxiv.org/pdf/2405.17978